In this post, I want to show how hypergraphs are a good intermediate representation for surfacing parallelism in imperative programs. Hypergraphs are a sort of intermediate representation for string diagrams [1] and they have been used as an intermediate representation for programming languages at least in [7], so we are not saying anything new here. My goal is to make this knowledge more accessible to compiler engineers since I think that their field could draw some concrete practical benefits from recent developments in Category Theory. I believe that the essence of modern IRs such as MLIR [8] and RVSDG [9] can be mathematically modeled by some sort of bimonoidal category as in tape diagrams [5] or mixed algebras [10]. More specifically, the data structure for exposing parallelism from [9] recalls what we do here with hypergraphs, motivated by an example we found in an old category theory book [10]. I think it is always interesting when theory and practice converge!
Let’s consider a simple code in Python:
1 | x = 1 |
Intuitively, we observe that the order of execution of some statements is not relevant. More specifically, as far as y is assigned before z, every other reordering does not change what the program does. For instance, another equivalent program is given by:
1 | y = 3 |
How can we represent a program in such a way that equivalent programs have the same representation? If we use an abstract syntax tree (AST) as an internal representation, equivalent programs would have different representations. An AST is a data structure that represents the syntax of a program. Think of syntax as the rules and structures that define how we can form well-formed programs in a language. An internal representation based on ASTs would follow how terms are laid out so that equivalent programs that are syntantically different would have different representations.
For this reason (but not only), compilers do not use the AST as an intermediate representation. For example, in MLIR [8], code blocks are represented in Single Static Assignement form where each variable is assigned exactly once and the order of assignments is not relevant because it is implicit and induced by the data dependencies between definitions and uses. In other words, syntatically different blocks have the same meaning if one can be written as the other just reordering assignments.
Something similar has been studied in applied Category Theory (e.g. [1]). String diagrams are a sort of AST on steroids: they are not trees, but, just like commands and expressions in programming languages, they are a formal graphical syntax that allows us to construct diagrams by inductively applying some basic compositional rules. If you are interested in more details, we refer to [6] for a gentle introduction where a detailed explanation is provided. As for ASTs, the structure of the diagram reflects the structure of how basic building blocks are composed. However, two string diagrams are considered equivalent if we can apply topological deformations of the wires that preserve the connections. This “rewriting” of diagrams based on these implicit equations is a form of syntactic manipulation. In [1] (and subsequent papers [2] and [3]), the authors show how hypergraphs are a data structure for string diagrams that makes these rewriting rules implicit. In other words, equivalent (up to some rewrite rules) string diagrams have the same representation as hypergraphs.
In a previous blog post, we talked about a categorical semantics for computer programs borrowed from [5]. In that case, we built a string diagram (or more precisely a string diagram of string diagrams) as an intermediate representation.
Can we design a better intermediate representation for programs where “equivalent” programs are represented in the same way? In other terms, can we represent a sequential program with a data structure that is the same data structure corresponding to its parallel version? The answer is positive and, surprise, surprise, we are going to use hypegraphs of hypergraphs as a representation for string diagrams of string diagrams. The benefit of using hypergraphs as an intermediate representation is that we don’t have to apply rewrite rules as we did in here for surfacing parallelism, but parallelism is implicit in the hypegraph data structure. In other terms, to paraphrase [7], the hypergraph intermediate representation absorbes the “parallism” laws.
Revisiting tape diagrams
In this section, we introduce a categorical semantics for IMP. We follow the approach based on tape diagrams described in [5]. However, we are changing it a little. More specifically, we build contexts dynamically and we consider only a particular case of tapes that allow us to simplify the explanation.
As we discussed elsewhere, in the context of programming languages, tape diagrams capture the idea of alternative computations. We use them to model if-then-else constructs. However, in structured programs, alternative control cannot go, so to speak, wild. Usually (I am over-simplifying a bit since I don’t consider break and continue), if-then-else blocks have a single entry point and a single exit point. This is not the case when we have arbitrary goto statements. In [5], this is captured by the concept of convolution. Convolution is a control diagram with single entry and exit points. Hence, we can represent convolutions as control diagrams nested in a data diagram, as illustrated in the following picture.
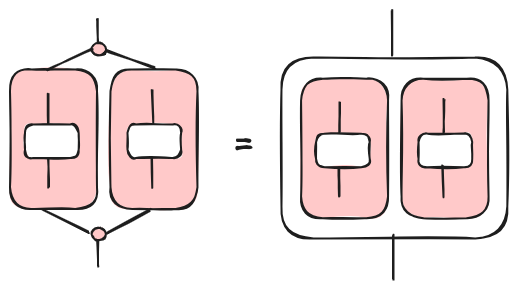
The benefit is that we can compose convolutions with data diagrams without the need of introducing $\otimes$ (aka green tapes in my previous post). We can do that because convolution tells us how we can split and merge control. So, we are restricting a lot the possible control flows and programs that can be represented. However, this is fine as far as we consider only structured languages.
The other change we are going to introduce is how typing contexts are built. In [5], expressions and commands are encoded into string diagrams by induction on the structure of well-typed terms. In other words, terms are well-typed with respect to a given fixed context. We are instead interested in building contexts in a more dynamic way. The reason is that we want to compute the minimal context for subterms because otherwise hypergraphs wouldn’t absorb parallelism. If it is not clear what I mean, I hope it will become so once more concrete examples are provided.
A program can be seen as a morphism $[y_j = t_j]_j$ from context $\Gamma = {x_i: T_i}_i$ to context $\Delta = {y_j: U_j}_j$ where $y_j: T_j \in \Delta$ and $\Gamma \vdash t_j: T_j$, as usual. Intuitively, $\Gamma$ is the input context that provides typing for free variables occurring in $t_j$, while $\Delta$ is the new context resulting from the execution of a program. In our setting, $\Delta$ usually extends $\Gamma$ with new variable definitions.
We need to pay attention when we define sequential composition of commands $C;D$ because it does not correspond to composition of context morphisms. For simplicity’s sake, we assume that contexts can always be merged over common names; in reality we should be concerned about type unification. This is the derivation for the context morphism of $C;D$.
$$
\frac{\Gamma \vdash C: \Gamma’ \quad \Delta \vdash D: \Delta’}
{\Gamma, \Delta \setminus \Gamma’ \vdash C; D: \Gamma’ \setminus \Delta’, \Delta’}
$$
Roughly, we need to propagate the inner contexts $\Gamma’$ and $\Delta$, and we should remove from $\Gamma’$ the variables that are redefined in $\Delta’$. Graphically, sequential composition is defined in the following way that might recall some parallel operators in process algebras with synchronization over a set of names.
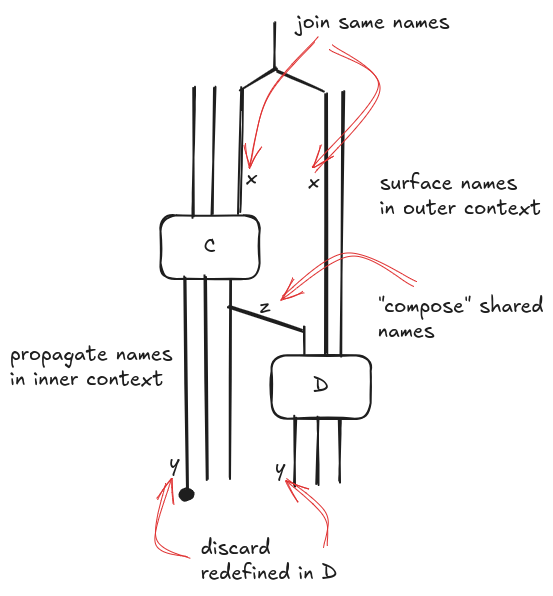
Note that we have omitted saying several things in order to keep it simple. First of all, wires are not contexts but types: we label wires with variable names just for clarity. In addition, we should swap wires because the order of wires matters.
Surfacing paralellelism, hypergraph version
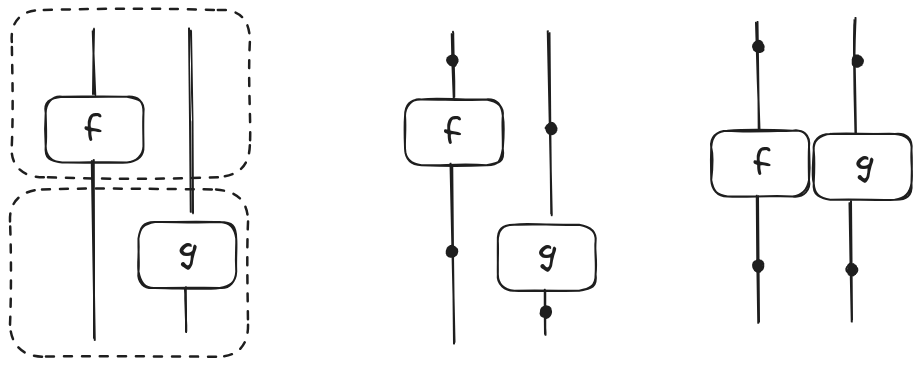
An hypergraph is a bipartite graph with two kinds of nodes: vertices and hyperedges. Intuitively, a hyperedge is an edge that connects more than two vertices. String diagrams can be represented as hypergraphs where wires are vertices and ground morphisms hyperedges. In the following picture, we show a string diagram (left) and its hypergraph (centre) for the morphism $(f \otimes id_U) ; (id_V \otimes g)$. Dotted boxes are not part of the string diagram; they represent the syntactic layout. The point here is that in a hypergraph only the connections between vertices and hyperedges matter and not their topological disposition. Hence, the hypergraph in the centre can be visualized as the hypergraph on the right.
Let’s consider the code fragment from our previous post and look how what we have learned so far can help us surfacing parallelism:
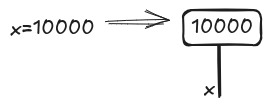
1 | x = 10000 |
First, we build a diagram for x=10000. The initial context $\Gamma$ is the empty set so we don’t have any input wire; instead, after the excution, a new context $\Gamma’$ with an element $x: \mathit{Nat}$ is created.
The diagram for y=10000 is built in a similar way. We want now to compose the two instructions in x=10000; y=10000. We need to use the operator sequence described in the previous section whose output is illustrated in the following picture.
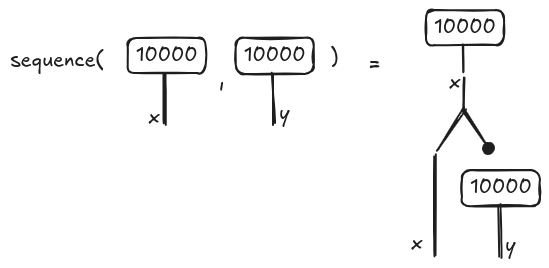
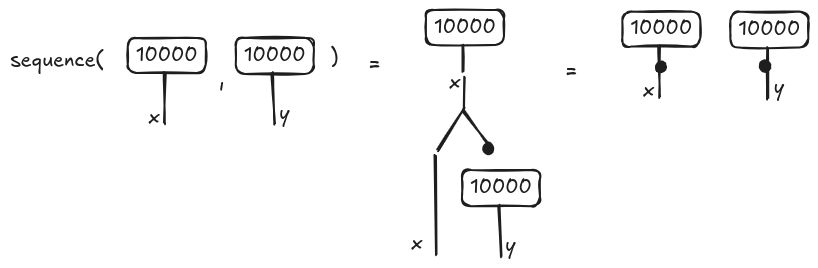
The diagram on the right is a string diagram, namely a syntactic object. If we encode the string diagram as a hypergraph, the visualization is simplified. In particular, since the two assignments are data-independent, they will be justaposed (meaning that they can be executed in parallel) as shown below on the very right.
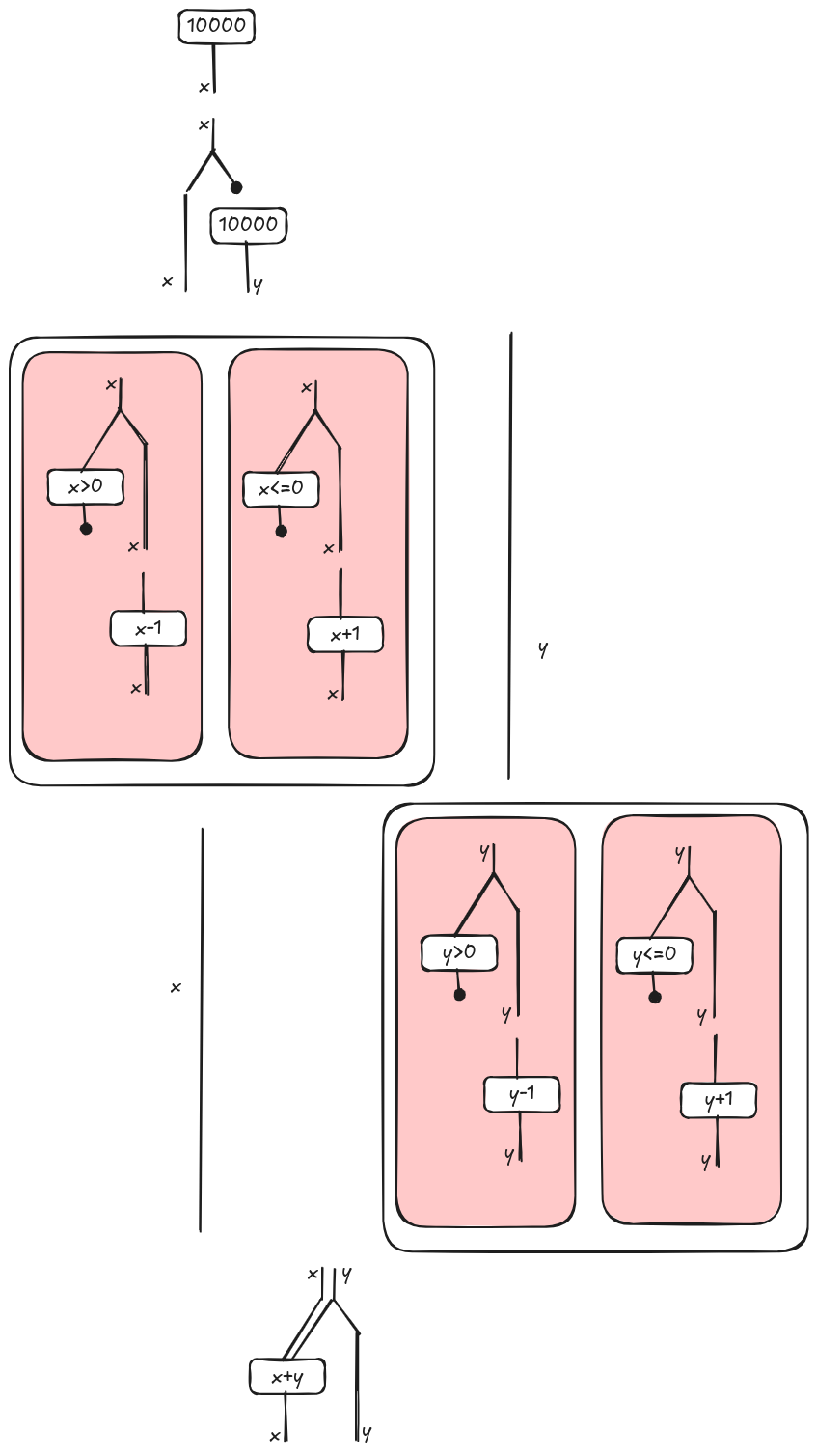
We can continue in a similar way to build the string diagram for the whole program. Note that we apply again the sequence composition when we meet the two if-then-else blocks. In this case, y (respectively x) if not used in the first (respectively second) block, so the block is in parallel with a wire, i.e. do nothing on y (respectively x).
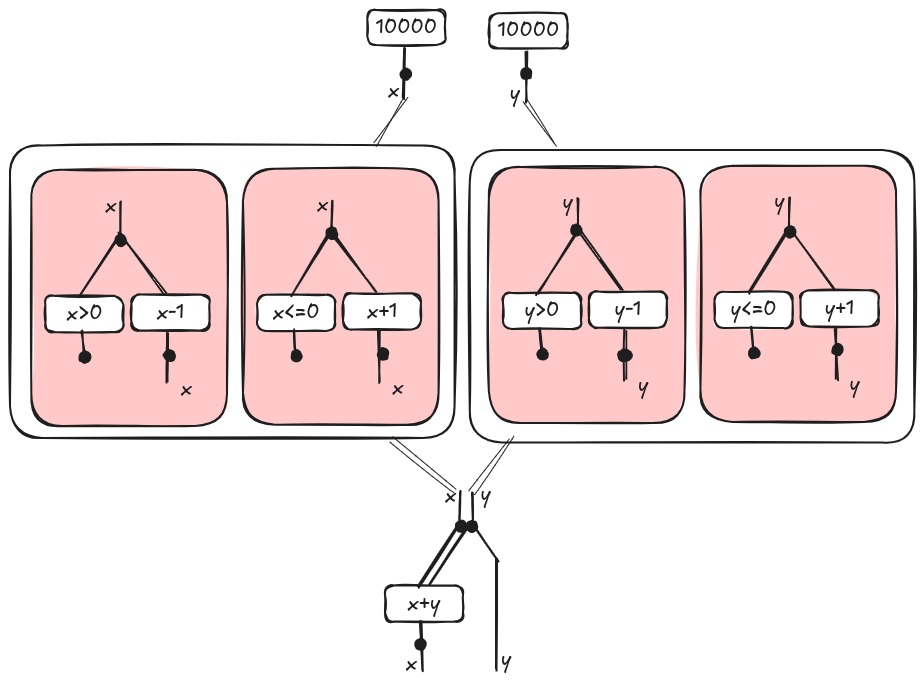
If we represent the string diagram above as an hypergraph, the inherent parallelism is exposed as illustrated here:
References
[1] Bonchi, Filippo, et al. “String diagram rewrite theory I: rewriting with Frobenius structure.” Journal of the ACM (JACM) 69.2 (2022): 1-58. pdf
[2] Bonchi, Filippo, et al. “String diagram rewrite theory II: Rewriting with symmetric monoidal structure.” Mathematical Structures in Computer Science 32.4 (2022): 511-541. pdf
[3] Bonchi, Filippo, et al. “String diagram rewrite theory III: Confluence with and without Frobenius.” Mathematical Structures in Computer Science 32.7 (2022): 829-869. pdf
[4] Wilson, Paul, and Fabio Zanasi. “Data-parallel algorithms for string diagrams.” arXiv preprint arXiv:2305.01041 (2023). pdf
[5] Bonchi, Filippo, Alessandro Di Giorgio, and Elena Di Lavore. “A Diagrammatic Algebra for Program Logics.” arXiv preprint arXiv:2410.03561 (2024). pdf
[6] Piedeleu, Robin, and Fabio Zanasi. “An introduction to string diagrams for computer scientists.” arXiv preprint arXiv:2305.08768 (2023). pdf
[7] Wilson, Paul. “CATGRAD: A Categorical Compiler for Deep Learning.” pdf
[8] Lattner, Chris, et al. “MLIR: A compiler infrastructure for the end of Moore’s law.” arXiv preprint arXiv:2002.11054 (2020). pdf
[9] Reissmann, Nico, et al. “RVSDG: An intermediate representation for optimizing compilers.” ACM Transactions on Embedded Computing Systems (TECS) 19.6 (2020): 1-28. pdf
[10] Stefanescu, Gheorghe. Network algebra. Springer Science & Business Media, 2000.